バベルの図書館は完成しない
Extended outer memory module
for my poor native memory.
Posts:
2026/01/06 前回記事から4年が経過しました、現状報告
2022/02/13 クラビスの CTO になりました
2020/09/28 gendoc という YAML からドキュメントを生成するコマンドを作った
2020/09/13 ISUCON10 の予選を 7 位で通過した
2019/12/01 Puma の内部構造やアーキテクチャを追う
2019/05/27 Golang の正規表現ライブラリの処理の流れをざっくり掴む
2019/04/29 InnoDB の B+Tree Index について
2019/04/29 InnoDB における index page のデータ構造
2019/04/28 InnoDB はどうやってファイルにデータを保持するのか
2019/01/06 Designing Data-Intensive Applications を読んでいる
2019/01/03 年末年始に読んだ本について、など
2019/01/01 Ruby から ffi を使って Rust を呼ぶ
2018/11/10 ブラウザにおける状態の持ち方
2018/07/01 Rust で web アプリ、 或いは Rust における並列処理
2018/05/14 なぜテストを書くのか
2018/05/13 Rust で wasm 使って lifegame 書いた時のメモ
2018/03/12 qemu で raspbian のエミュレート(環境構築メモ)
2018/03/12 qemu で xv6 のエミュレート(環境構築メモ)
2018/03/03 Ruby の eval をちゃんと知る
2018/02/11 Web のコンセプト
2018/02/03 Rspec のまとめ
2018/02/03 Ruby を関数型っぽく扱う
ISUCON10 の予選を 7 位で通過した
結果
ニル侍 というチームで ISUCON10 に出ました、結果は 7 位でした(表示順がそのまま順位という理解でいいんだよね?)
全 490 チーム参加ということなので満足のいく結果でした、最終得点は 3134 点でした
せっかく予選通過したので予選参加に関して記録を残してみようと思います
記憶をたどりつつ slack 見つつ github 見つつで振り返っていますが特に競技中にやったことや点数に関して不正確な記述があるかもしれないです(時系列が前後しているとかやった最適化と点数の対応が間違っているとか…)
チーム
- daikimiura
- Ryo Kubota
- ふるはま
というメンバーでやっていました、言語は Ruby です
(2020/09/14 追記) Ruby で本選にいけたの僕たちのチームだけなんですね… Go 率高すぎ…
もともと ISUCON8 に僕以外の 2 人のメンバーで参加していたらしくて、 ISUCON9 にはそこに僕も合流して今回と同じメンバーで参加という経歴のチームです
(ちなみに ISUCON8 も ISUCON9 も最終得点は 0 点でした、 ISUCON9 では盛大にバグらせて点数付かなくて本当につらかったです)
準備編
ISUCON9 の反省として
- 自動化しておける部分は自動化しておくことでオペミスを避けるのとオペミス起因の想定外の事象であたふたしないようにしておきたいね
- チーム内の特定の誰かしか触れない領域はなるべく減らしておこうね(僕はインフラや nginx を全然触れなくてポンコツだった)
というのがありました
ちょうど 2020/05 に僕が所属している会社で社内 ISUCON 的な大会があり、いい機会だと思って反省を踏まえつつ 1 人で出場してみることにしました
鍵配置からツールの DL からデプロイまで全部 make で自動化して臨んだので快適に競技はできました
しかしまたバグらせてここでも時間内の結果は 0 点でした、またかよって感じですね
競技時間終わってからちょっとやってみたらバグが取れて点数的には圧倒的 1 位になりました、競技の成績としては全く意味ないですけどやろうとしていることが大きく間違ってなく、一人でも時間をかけたらそこそこできるということがわかって良かったです
余計な話はさておきこの時作った自動化スクリプト群を isukit と名付けて isucon10 で利用するものの土台として 3 人で準備をしていきました
当日の分担は
- daikimiura: アプリの web サーバの入れ替え、アプリの改善
- Ryo Kubota: 3 台構成、 nginx レイヤの最適化、インフラレイヤのパラメータ最適化など
- ふるはま: アプリの改善
みたいな想定でいました(実際この通りやった)
本番編
開始前
モンスターとアイスコーヒーとほうじ茶と飲むヨーグルトとのど飴をコンビニで買って臨みました
液体ばっかりだしカフェイン摂りすぎですね
序盤 (12:20-15:00 くらい)
コードの git 管理や 3 台構成への変更や unicorn -> puma の変更などをやっていたと思います、僕はこの作業は一切絡んでなくて DB スキーマとかアプリコードとか眺めてレイヤ問わず思いついた最適化の案を scrapbox に書き出すということをしていました、あと DB のデータをローカルに落としてきてローカルで EXPLAIN できるようにするというのをシュッとやりました
ベンチマークが実行できるようになってからは alp や pt-query-digest の結果を眺めて最適化のターゲットをまずエンドポイントレベルで見てみていました
僕はとりあえずトップページで発行されるクエリのためにインデックスの追加を行いました
しかし僕が普段 EXPLAIN の結果を見慣れていないせいで possible_keys にインデックスが追加されただけで喜んでしまって実際には意味のないインデックスを追加してる部分もありました、おめでたいやつめ
椅子の詳細画面に出てくるおすすめ物件のクエリが気持ち悪くて意味のなさそうな条件がいっぱいついてたのでそれを直していました(椅子の 3 辺のうち小さい 2 辺がドアを通るかどうか調べるのみで良いはず)
中盤 (15:00-19:00 くらい)
途中からはエンドポイント単位でのレスポンスタイムを眺めつつ合計実行時間(回数 * 平均クエリ実行時間)の多いクエリを眺めて色々していきました
なぞって検索のコードを読んでいてアルゴリズム賢いなって思ったんですけど N 回もクエリ投げてて悲しい気分になったのと、多角形の頂点と対象の物件の存在する点がわかっているのでアプリ側でなんとかなりそうだねという話を daikimiura としました
20 秒くらいググったら java のサンプルコード付きの賢い判定アルゴリズムが出てきたので(対象の点から x 軸に平行な半直線を引いて多角形の辺との交点の数の偶奇を調べるやつ) daikimiura に実装をお願いしました
features カラムの LIKE 検索が気になっていたのでデータ構造を変えようかと思い(結局最後まで手を付けなかった)、その手始めに椅子と物件の追加エンドポイントで起きている N 回 INSERT を bulk INSERT に直すということをしていました(ちょくちょくバグらせてしまって申し訳なかったです)
ここまで終わったあたりで 900 点くらいだったと思います
Ryo Kubota が nginx で bot のリクエストを弾いたり multi_accept したり MySQL のバッファプールを広げたりしてくれて 1000 点くらいになりました
これは完全に余談ですが、途中みんなでデプロイ完了通知を音で把握できるようにしたいねと話していてデプロイスクリプトに say コマンド挟んでみたところ、間違って 3 台それぞれのデプロイ完了時に音声が流れるようになっており、デプロイを開始したら音声が流れた回数を覚えておき 3 回目が流れたらベンチマークジョブをエンキューするという謎の認知負荷が生まれた時間帯があり面白かったです(すぐ直しました)
追加で estate にいくつかインデックスはって puma のワーカー増やして 1600 点くらいになりました
このあと estate テーブルの popularity DESC, id ASC なソートが気になり始めたので正規化を崩して十分大きい数から popularity を引いた数を入れるカラムを追加して昇順ソートできるようにしました(感想チャットでもありましたが考えてみると int 型のカラムなので単に * -1 するだけで良かったのでした)
非正規化カラムの名前は 7 秒くらいで考えたので dec_pop なんてひどい名前を思いつきそのまま採用されました、もし正気の僕がレビュアーだったらこんなカラム名絶対通さないです(ちなみに MySQL 8 なら降順インデックスが効くのはその時話していたんですが 5.7 からの入れ替え大変そうだしそもそも 8 使った経験ないしでやめました)
多少バグらせつつも無事直せてこの時点で 2000 点くらいだったと思います
さらに Ryo Kubota による puma のワーカーと MySQL のバッファプールのサイズ調整で 2300 点くらいになりました
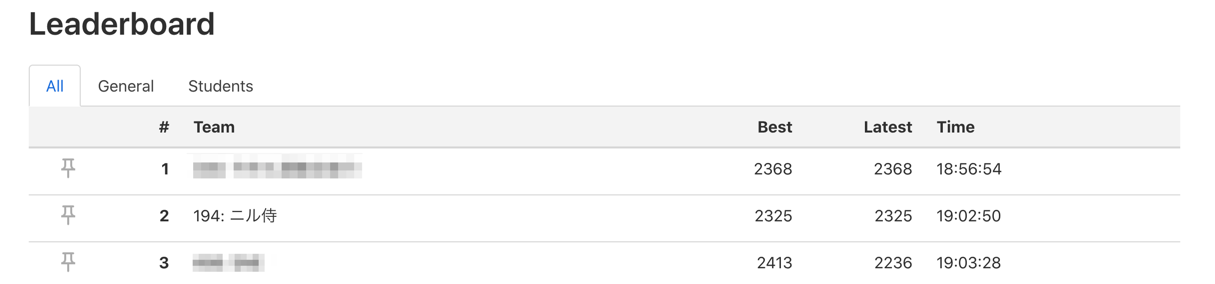
この時間帯に一時 latest の点数ランキングで 2 位になっていてこんな景色なかなか見れないなと思わずスクショしました、ダサすぎますね
終盤 (19:00-21:00 くらい)
estate の popularity の降順ソートに対して入れた最適化が簡単だったので chair にも適用したろと思ってやったら点数が下がってよくわからなかったです
序盤で追加したが今となっては不要なインデックスも結構ありそうだったので一度お掃除しました、また MySQL の performance_schema が有効になっているのに気づいてしまったので無効にしました、これで 2500 点くらいになりました
DB でやってる CPU インテンシブな処理をアプリサーバーに逃せないかなと思ってソート処理をクエリではなくアプリレイヤでやろうとする最適化を入れてみましたが点数はむしろ下がったのでやめました、ちーん
なぞって検索の最初に多角形が入る最小の長方形分の物件を取ってくるところがありますが、なぜか (longitude, latitude) の順の複合インデックスだとインデックスが利用されて ICP になるのに (latitude, longitude) の順の複合インデックスだとインデックスが利用されないという問題が起きていることに偶然気づいて順番を直しました(このときはちゃんと理解していなくててっきりインデックスは使われてるけど ICP になるケースとならないケースがあるのだと勘違いしていました。実際には optimizer の気分でそもそもインデックスが使われないという事象だったので FORCE INDEX(idx) すれば問題ない話でした)
さらに puma を production モードにしたり MySQL のスロークエリを切ったり puma のスレッド数の調整などを行って 2700 点くらいでした
このとき偶然 nginx の error ログを眺めていたら、クライアントからのリクエストボディがバッファに乗り切らなくてディスクに一時ファイルを作っていることに気づいて慌てて Ryo Kubota に client_max_body_size を設定してもらいました、調整もしつつ 3000 点ちょっと出ました
puma のスレッド数を調整しつつ再起動試験を 20:30 になってようやく行い(再起動してダメだったらどうするつもりだったんだ…)、最終的に 3100 点ちょっと出たのでもう大丈夫かなと思って終わりにしました
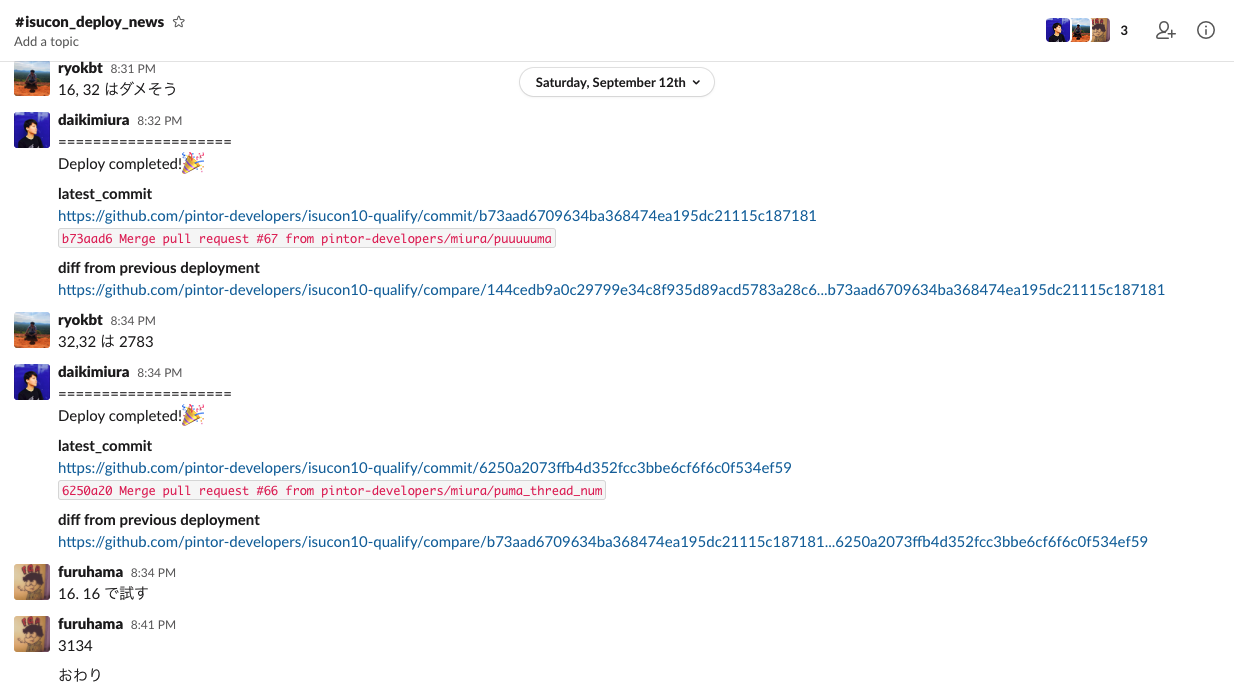
準備編で触れ忘れていましたが daikimiura がデプロイスクリプトをいい感じにしてくれてデプロイ時の HEAD のコミットやデプロイ前後の diff を slack に投げるようにしてくれていたのが非常に神でした
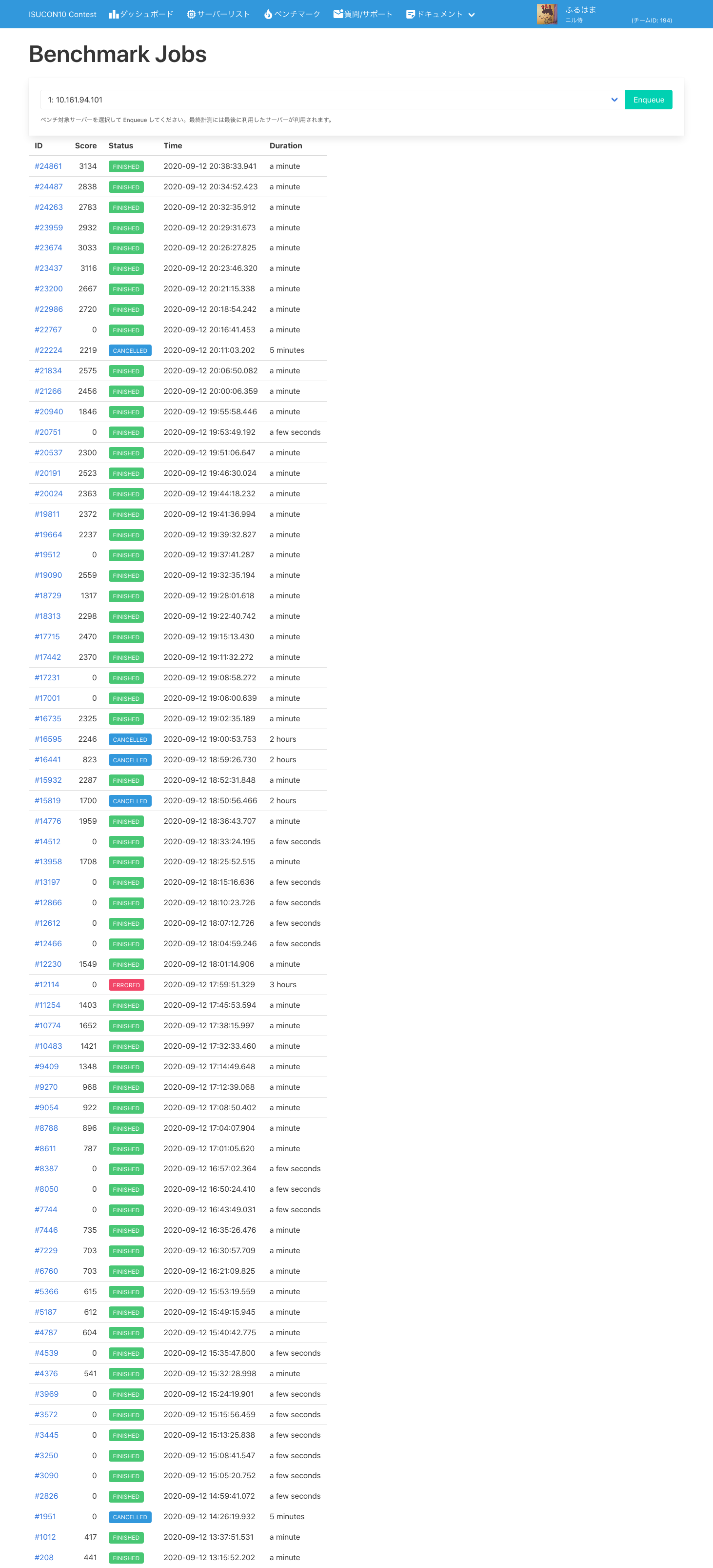
最終的に僕たちのベンチマークの点数の推移は以下の通りでした
おわりに
僕が DB(MySQL) 好きというのもあり特にそう思うのかもしれませんが今年の予選問題はすごく面白かったです
とはいえもうちょっとアプリケーションコードちゃんと読んだら SELECT FOR UPDATE を UPDATE WHERE で置き換える最適化なんかは思いついたかもしれなくて、意外とちゃんとコード読めてないなと思いました、反省です
終わってみてサーバー入って振り返っていたら innodb_flush_log_at_trx_commit とか innodb_flush_method とか変えるの忘れてたことに気づきました、もしかするともうちょっと点数出たかもしれないですね
個人的に今年はちゃんと変更を小さくしてかつまめに revert していけたのが良かったです、バグらせずに入れていける(破壊的すぎない/実装難度が高すぎない)最適化案を選び取るのが上手くいったのも良かったです、やっぱ時代はインクリメンタルに小さな変更を入れていく開発スタイルですよね、知らんけど…
さて本選ですが今回運良く進めたのに今回に限って(?)オンラインでの本選開催ということで残念です、他の会社のオフィス行ってみたかった。今の世の中の状況を考えると仕方ないですね
まあでもそんなことより何より ISUCON の問題を 2 つも解くことができるのが本当に最高です、楽しみすぎる、本選も気合いとエナジードリンクを入れて頑張りたいと思います
運営のみなさんはトラブルもあり大変だったと思うんですが、昼過ぎの開始となったことで ISUCON に出題される典型的な難問の一つである「競技中の昼飯どうするか」と向き合わなくて良かったので朝の開始よりパフォーマンス出ていたはずなのと、開始直後にベンチが回らないことで落ち着いて問題と向き合えたので、個人的には悪いことばかりではなかったです。予選運営ありがとうございました
2020/09/13 22:12tags: isucon - ruby - mysql
This site is maintained by furuhama yusuke.
from 2018.02 -