バベルの図書館は完成しない
Extended outer memory module
for my poor native memory.
Posts:
2026/01/06 前回記事から4年が経過しました、現状報告
2022/02/13 クラビスの CTO になりました
2020/09/28 gendoc という YAML からドキュメントを生成するコマンドを作った
2020/09/13 ISUCON10 の予選を 7 位で通過した
2019/12/01 Puma の内部構造やアーキテクチャを追う
2019/05/27 Golang の正規表現ライブラリの処理の流れをざっくり掴む
2019/04/29 InnoDB の B+Tree Index について
2019/04/29 InnoDB における index page のデータ構造
2019/04/28 InnoDB はどうやってファイルにデータを保持するのか
2019/01/06 Designing Data-Intensive Applications を読んでいる
2019/01/03 年末年始に読んだ本について、など
2019/01/01 Ruby から ffi を使って Rust を呼ぶ
2018/11/10 ブラウザにおける状態の持ち方
2018/07/01 Rust で web アプリ、 或いは Rust における並列処理
2018/05/14 なぜテストを書くのか
2018/05/13 Rust で wasm 使って lifegame 書いた時のメモ
2018/03/12 qemu で raspbian のエミュレート(環境構築メモ)
2018/03/12 qemu で xv6 のエミュレート(環境構築メモ)
2018/03/03 Ruby の eval をちゃんと知る
2018/02/11 Web のコンセプト
2018/02/03 Rspec のまとめ
2018/02/03 Ruby を関数型っぽく扱う
ブラウザにおける状態の持ち方
背景
このブログをちょこちょこいじっている中で、普段 web アプリケーションを作っている割にはブラウザでの状態の保持の仕方を知らないなと思った。
web の一つ一つの通信はなるべくステートレスとなるように作られているし、 web アプリケーションにおいて「状態を保持したい」という欲求は、 特定のブラウザ内部に、それに紐づく形で保持したいというよりも、もっと長い期間において状態を持ちたい場合が多い。
すなわちクライアント側ではなくサーバ側において、データベースやファイルシステムのような仕組みを利用することが多い。
とはいえ複数リクエストをまたいでもクライアントが同一であることを示すために、伝統的に利用されている cookie のような仕組みは、 session というもう少しセキュアでサーバ側に都合の良い形で利用している。
という前提の上で、現代的なブラウザの実装の中では cookie の他にもクライアント側に状態を持たせる仕組みがありそう。
利用シーン、モチベーションを探りながらわかる範囲でまとめてみたいと思う。
(各ブラウザの対応状況にまで食い込むと際限ない話になりそうなので Mozilla 好きとしてざっと MDN みてまとめるよ)
cookie
cookie の復習です。
上にも書いたけど cookie とは 複数の http リクエストをまたいでサーバとクライアントで状態を保持する仕組み と言っていいと思う。
昔のブラウザの実装だと、クライアント側で状態を保持する仕組みが cookie しかなくて、いろんな情報を cookie に持たせていたみたい。
しかし cookie にナイーブにいろんな情報を載せてしまうと、クライアント側が cookie を勝手に改変することでセキュリティのリスクが生じたり、サーバ側の想定していない形のリクエストがきてしまうなど、サーバにとっての不都合が生じた。
そこで cookie には最低限クライアントの同一性を検証するための値のみを持たせて、状態はサーバ側でのみコントローラブルな形にしようと頑張ったのが session という仕組み。だと理解している。
またもう一つの欠点として、 cookie は全てのリクエストに乗せて通信を行うので、ネイティブアプリケーションと対等なレベルまで UX を向上させる文脈や、或いはモバイル端末との通信のような不安定かつ帯域の少ない通信において、非効率になるパターンが存在した。(そんなに毎回全部使わないよ!みたいな)
特に後者の問題点の解決のために localStorage や sessionStorage という仕組み(合わせて Web Storage と言われるらしい)や、 indexedDB という仕組みが提供されるに至ったのでした。
Web Storage
cookie の抱える問題点のうち、おそらく主に通信に載せるデータの最適化のために登場したのが Web Storage という名前の一連の API なんだと思う。
こいつは sessionStorage というものと localStorage というものから構成されている。
sessionStorage
sessionStorage というのは、ブラウザがページを一度開いて、そのあとブラウザのプロセスが死ぬまでの間の期間、情報を保持する仕組み。
現代的なブラウザは「1 タブ 1 プロセス」の対応関係で機能しているので、新しいタブを開くと sessionStorage にあるデータは保持されない。
一般にキャッシュというのはマスタとレプリの同期を行うのが難しいので、使い勝手を考えて、 session という限定的な時間単位において有効な、状態の保持の仕組みがコレだと言えるだろう。
sessionStorage の API を眺める限り、インターフェースはシンプルな KVS となっている。
localStorage
localStorage に蓄積されるデータには期限がなくて、同じ origin に対してブラウザを閉じてもまた開けば保持し続けてくれている仕組み。
ブラウザのプロセスをまたいで利用できるということは、複数タブで同時に共有みたいなこともできちゃうんだろうか。
と思って試してみた。(これも KVS 的インターフェース)
-
同じ origin のタブを 2 つ開いてコンソールを起動してみる
片方で適当に setItem する
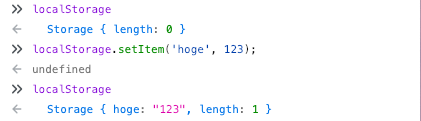
もう片方でその item が存在することを確認

もちろん、一回ブラウザのプロセスを親プロセスから丸っと殺しても、再起動したら残っている

ひええ〜〜(便利だけどこわい)
上に書いたように、サーバ側のデータとの同期が難しいし、クライアント側にずっと情報を残しておくというのはサーバ側としては結構嫌だと思うんだけど、どうやってコントロールしているんだろう。不具合を仕込んでしまった時にそれを制御するのが難しかったり、セキュリティ的にもあんまりよくなかったりすると思うんだけどな。
localStorage の問題点
気になったので調べてみた。
まず localStorage はページ読み込み時に同期的に読み込まれるみたいなので、たくさん情報を持たせるとページのレンダリングが遅くなる可能性がある。
たくさんのタブで同じ origin のページを開いている場合に、それらの間での localStorage の同期に時間がかかる問題というのもあるらしい。ディスク IO が発生するからさらに遅くなる可能性がある。
(一応 Async Local Storage なるものの Proposal が出てたりするので、気になる人はそっちもチェキラしてください)
さらには、クライアント側の localStorage の空き容量がどれくらいあるのかを知るためのすっきりとした方法がないという問題点があるそう。
そもそも一回しか行かないサイトたちにがんがん localStorage を利用されると、どんどんブラウザの起動が遅くなるという悲しい問題も、、、。
indexedDB
Web Storage API に対する愚痴ブログをみていると、 Web Storage の至らない点を踏まえて次の夢を託されたのが indexedDB という構図に見える。
KVS 型のデータ保持を行う Web Storage はデータを全て toString() して保持していることもあり、もっと複雑な構造を持つデータをたくさん持ちたい場合に使い勝手が悪くなるという問題があった。
すごくシンプルに言えば、そうしたデータの構造の複雑さやデータの数の多さを解決するために生まれた API が indexedDB という理解で良さそう。
indexedDB オブジェクトデータベースで、 RDBMS でいうところのテーブルのような ObjectStore という概念が存在する。
ObjectStore は KVS 型のデータの保持を行うがスキーマを持つことができて、そこに保持される Object に対して、どの property を key として扱うかを指定することができる。(RDBMS に当てはめることが正しいのかわからないけど PrimaryKey みたいなものだと思う)
さらにトランザクショナルな書き込みができるし、ある ObjectStore とその Object 群に対して key 以外の property で index を張ることができる。
僕は RDBMS の、それも mysql を中心に DB を利用してきたので他の RDBMS や KVS がどうなっているのか詳しくないけど、この仕組みは JavaScript と相性が良さそうだしかなり便利そうだ。
で、indexedDB に対する操作は request という単位で行われて、 request の状態の変化に応じてコールバックを呼び出すような形で処理を進める API 仕様となっているみたい。
-
Web Worker という名前のついた一連の API があって、 web ページのレンダリングやメインスレッドでの処理から切り離して、非同期に色々な処理をやろうという流れがある。 indexedDB はその中の一つのトピックとして実装されたもののようだ。
その根本のコンセプトにしたがって indexedDB に対する操作は非同期に行えるようになっている点も、 Web Storage と比較して優れている点だと言えるんだと思う。
具体的な使い方はパッとコンソールでやるには難しかった。
あとでしっかりスクリプト書いて実行してみようと思う。
MEMO: https://developer.mozilla.org/en-US/docs/Web/API/IndexedDB_API/Using_IndexedDB
CacheStorage
まだ Working Draft の段階で、主要なブラウザが全部実装しているか怪しいんだけど、 Service Workers API の中に Cache Storage というものがある。
けどほんとに一部しかないし、まだ標準化の途中なんだと思う。 w3c における仕様の策定の進み方とかも軽く勉強しないと、温度感がわからないな…。
他も軽く調べてみたけどまだ情報が少なくてよくわからなかった。
僕の現状の理解だと、 ServiceWorker に対して Cache オブジェクトを明示的にメインスレッドから渡すための、スレッド間での共有バッファ的な役割を持つ API のことを CacheStorage と呼んでいる、というように読めた。
まとめ
というわけで web におけるクライアント側に状態を持たせる仕組みは、より複雑でデータ構造をより高速で安全に扱うに耐えうる形に進化してきたっぽい。
より複雑なデータ構造という観点では JavaScript のオブジェクトを一旦文字列に変換することなくそのまま扱えるような storage API が出てきたし、
より高速な処理という観点ではメインスレッドから IO を分離して ServiceWorker に色々頑張らせる API が出てきている。
一口にブラウザ側での情報の保持と言っても、初期の cookie とはまるで異なる API が提供されており、
用途もパフォーマンスの向上やオフラインでのページレンダリングなど発展的なものになってきていて、
ブラウザ自身が内部に小さな web アプリケーションサーバを再現していこうとしているかのようだ。
(CPU がメモリへのアクセスだと遅すぎるから内部にキャッシュを保持しているのと似てる。最適化によってどんどん複雑になっていく)
このテーマは結構面白かったので、次は初回のロードをなるべく速くするための試みに関してまとめてみたい。
-
参考:
- HTTP cookies - HTTP: MDN
- Web Storage API: MDN
- Web Storage: HTML Standard whatwg
- sessionStorage: MDN
- localStorage: MDN
- Async Local Storage: Github
- There is no simple solution for local storage
- Test of localStorage limis/quota
- Web Workers API: MDN
- IndexedDB API: MDN
- Basic Concepts - IndexedDB: MDN
- Using IndexedDB: MDN
- Indexed Database API 2.0: w3c
- cacheStorage: MDN
- Service Workers Nightly: w3c
tags: web - browser - javascript
This site is maintained by furuhama yusuke.
from 2018.02 -